Lecture 7 - (03/03/2026)
Today’s Topics:
Multiple Linear Regression
Gradient Descent
Feature Engineering
Multiple Linear Regression¶
Linear Algebra¶
So far we have worked with 1-D linear regression where each observation has only one feature which allows us to use simple pointwise multiplication for each operation.
which can also be represented as
Since we are working with dataframes that have multiple features, we will need to introduce something a little bit more powerful for our linear regression, matrices:
Despite the change in notation, they behave the same way, and we can simplify this by writing:
Feature Selection¶
In many data sets there may be several predictor variables that have an effect on a response variable. In fact, the interaction between variables may also be used to predict response. When we incorporate these additional predictor variables into the analysis, the model is called multiple linear regression.
import numpy as np
import pandas as pd
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn import linear_modelcali = datasets.fetch_california_housing()
X = pd.DataFrame(cali.data, columns=cali.feature_names)
y = pd.Series(cali.target)
X.head()y.head()0 4.526
1 3.585
2 3.521
3 3.413
4 3.422
dtype: float64X.describe()For each row of X and y it can be interpreted as:
Entry 0 of X:
Median Income: $83,252
Age of Household: 41 years
Average Rooms: 6.98
Aveage Bedrooms: 1.02
Population: 322
Average Occupiants: 2.55 persons
Latitude: 37.88
Longitude: -122.23
Entry 0 of y:
House Price: $452,600
What features in X do you think contribute to the value of y?
Let’s guess that age of the house, number of rooms, and number of bedrooms all contribute to it.
Our new linear regression function will be:
One of the most important things to notice about this equation is that each variable makes a contribution independently of the other variables. This is called additivity: the effects of predictor variable are added together to get the total effect on PRICE.
linreg = linear_model.LinearRegression()linreg.fit(X[['MedInc', 'HouseAge', 'AveRooms', 'AveOccup']], y)linreg.score(X[['MedInc', 'HouseAge', 'AveRooms', 'AveOccup']], y)0.5137125846287833Interaction Events¶
Suppose we discovered that people who live in upper california (higher latitude) and had older houses (higher house age) tended to have cheaper houses, but people who lived in lower california with newer houses had more expensive houses. This chould indicate an interaction event on the response. When there is an interaction effect, the effects of the variables involved are not additive.
Different numbers of variables can be involved in an interaction. When two features are involved in the interaction it is called a two-way interaction. There are three-way and higher interactions possible as well, but they are less common in practice. The full model includes main effects and all interactions.
Often in practice we fit the full model to check for significant interaction effects. If there are no interactions that are significantly different from zero, we can drop the interaction terms and fit the main effects model to see which of those effects are significant.
Collinearity¶
Collinearity(or Multicollinearity) occurs when two variables or features are linearly related, i.e. they have very strong correlation between them (close to -1 or 1). Practically this means that some of the independent variables are measuring the same thing and are not needed. In terms of linear algebra, this is considered a linear dependance, and one of the variables can be removed.
In our case, rooms and bedrooms are likely linearly related therefore it would be redundant to include both of them in our model so we can opt to remove one of them.
Gradient Descent¶
When we are modeling a graph we tend to follow the following procedure:
Split your data into pieces for training & validation
Select a model
Select a loss function
Minimize the loss function, using training data.
Validate your model with reserved test data
But how do we minimize the loss function?
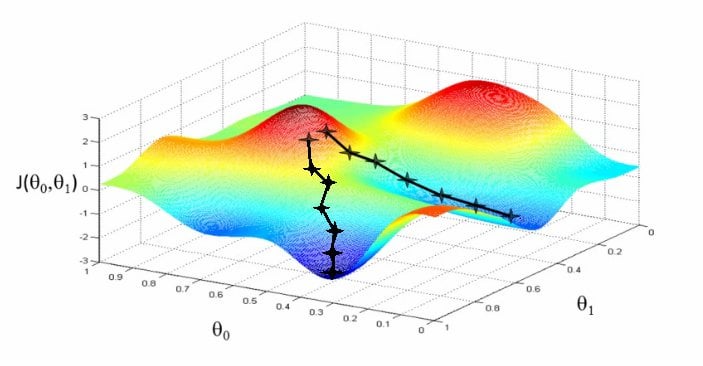
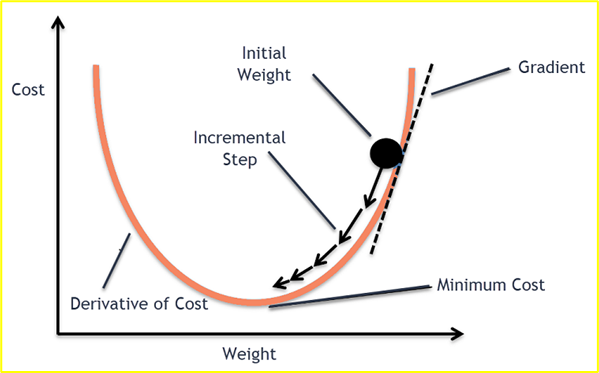
The idea:
Slide down the hill in the direction of least resistance.
Moving forward, to find the lowest error(deepest point) in the loss function(with respect to one weight), we need to tweak the parameters of the model. Using calculus, we know that the slope of a function is the derivative of the function with respect to a value. This slope always points to the nearest valley!
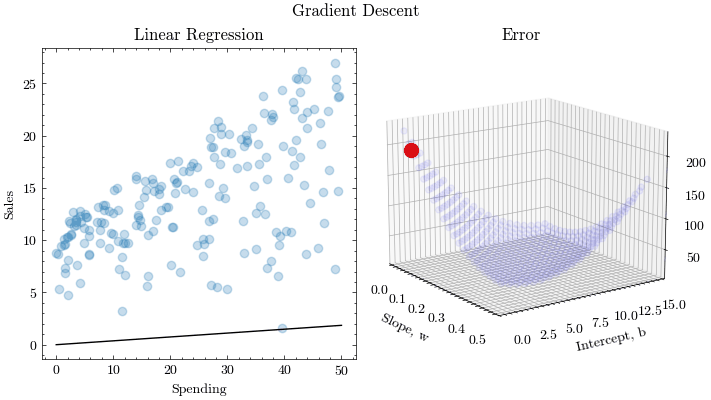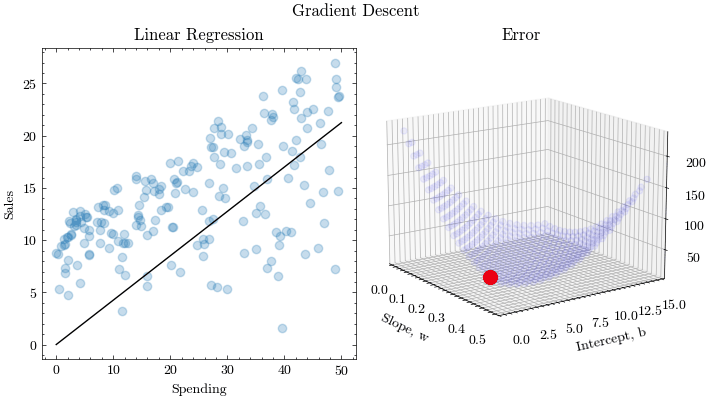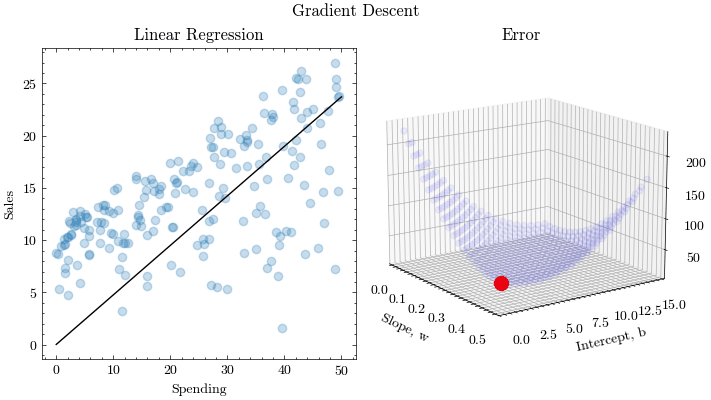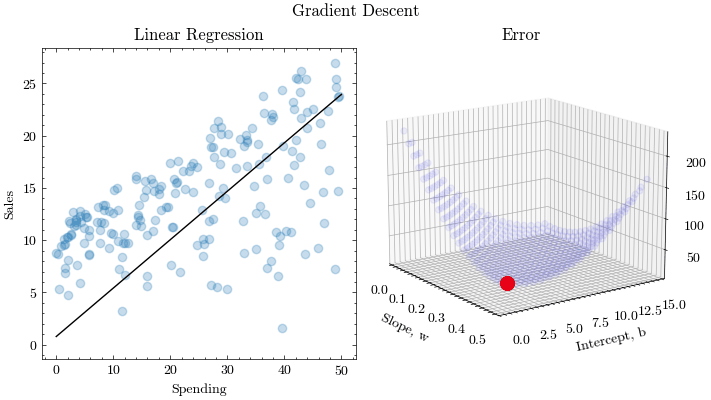
If we try to think of it in visual terms, our training data set is scattered on the x-y plane. We are trying to make a straight line (defined by ) which passes through these scattered data points.
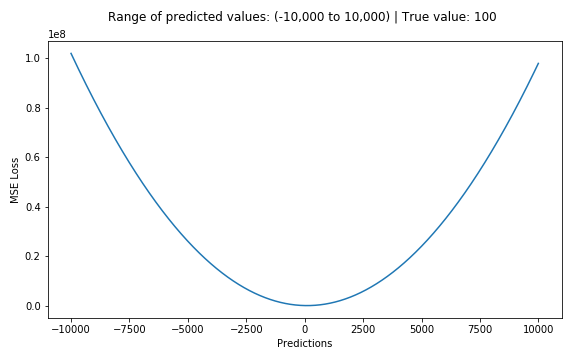
Our objective is to get the best possible line. The best possible line will be such so that the average squared vertical distances of the scattered points from the line will be the least. Ideally, the line should pass through all the points of our training data set. In such a case, the value of the error function will be 0.
def mse_loss(x, y, w, b):
return np.mean(np.square(y - (w * x + b)))In each epoch of gradient descent, a parameter is updated by subtracting the product of the gradient of the function and the learning rate . The learning rate controls how much the parameters should change. Small learning rates are precise, but are slow. Large learning rates are fast, but may prevent the model from finding the local extrema.
$$ X_{n+1} = X_n - lr* \frac{\partial}{\partial X} f(X_n)
Since we are finding the optimal slope () and y-intercept () for our linear regression model, we must find the partial derivatives of the loss function with respect to and .
We repeate this process until there is no difference between and which implies that the model has converged to some minimum loss value.
Enough about this, let’s practice it with a game