Lecture 4 - (10/02/2026)
Today’s Topics:
Feature Types
Linear Regression
Data Wrangling
Feature Types¶
import pandas as pd
df = pd.read_csv("https://raw.githubusercontent.com/mwaskom/seaborn-data/refs/heads/master/taxis.csv")
dfThe structure of a dataset is the arrangement in rows and columns or our mental representation of the data.
What does a row of the table represent? The answer to this question is what we refer to as the granularity of the table.
Nominal feature: represents “named” categories that do not have a natural ordering. Examples:
Dog breed groups: (herding, hound, non-sporting, sporting, terrier, toy)
Operating systems: (Windows, MacOS, Linux)
Ordinal feature: represents ordered categories. Examples:
T-shirt size (small, medium, large)
Likert-scale response (disagree, neutral, agree)
Level of education (high school, college, graduate school)
These are subtypes of categorical data or qualitative data.
Quantitative feature: represents numeric amounts or quantities, both continuous and discrete.
Examples:
Height measured to the nearest cm,
Price reported in US Dollars
Number of siblings
Currently the focus of our class will be on quantitative features and doing analysis on those features, we will explore ways to apply analytic methods to qualitative data later in the course
Linear Regression¶
import plotly.express as px
px.scatter(df, x='distance', y='fare')A regression analysis determines the relationships between a dependent variable (often called ) and an independent variable(s) (often called ).
The results are often used for prediction, as it is the simplest example of supervised machine learning.
We will start with linear regression.
Goal: find a linear relationship between the independent and dependent variables:
Score each line with how close the actual and predicted y-values are (using RMSE for the loss function).
The best scoring line is called the regression line.
import numpy as np
import plotly.graph_objects as go
from plotly.subplots import make_subplots
from sklearn.metrics import mean_squared_error
x = df["distance"].values
y = df["fare"].values
order = np.argsort(x)
x_sorted = x[order]
y_sorted = y[order]
# good model
coef_good = np.polyfit(x, y, 1)
y_pred_good = np.polyval(coef_good, x_sorted)
rmse_good = mean_squared_error(y, np.polyval(coef_good, x))
# bad model
coef_bad = [0.1, np.mean(y)]
y_pred_bad = coef_bad[0] * x_sorted + coef_bad[1]
rmse_bad = mean_squared_error(y, coef_bad[0] * x + coef_bad[1])
fig = make_subplots(
rows=1, cols=2,
subplot_titles=[
f"Good Linear Fit<br>RMSE = {rmse_good:.2f}",
f"Bad Linear Fit<br>RMSE = {rmse_bad:.2f}",
]
)
for col in [1, 2]:
fig.add_trace(
go.Scatter(
x=x, y=y,
mode="markers",
marker=dict(size=5, opacity=0.6),
showlegend=False
),
row=1, col=col
)
fig.add_trace(go.Scatter(x=x_sorted, y=y_pred_good, mode="lines", name="Good Fit"),
row=1, col=1)
fig.add_trace(go.Scatter(x=x_sorted, y=y_pred_bad, mode="lines", name="Bad Fit"),
row=1, col=2)
fig.show()
The correlation coefficient gives a single number measuring the association between the variables.
Regression gives a function that computes an estimate for each input.
The differences, or residuals (red lines), can give additional information.
Linear Models¶
import plotly.figure_factory as ff
url = "https://raw.githubusercontent.com/mwaskom/seaborn-data/master/tips.csv"
tips = pd.read_csv(url)
tips['percent'] = tips['tip'] / tips['total_bill'] * 100
fig = ff.create_distplot([tips['percent']], ["Percent Tips"])
fig.add_vline(x=15, line_color = 'purple', line_dash = 'dash')
fig.show()Introduced a new variable: Percent Tip Amount.
Asked what’s a good estimate, , for percent tip?
Seeking a single number, or constant model, for percent tip.
px.scatter(tips, x='total_bill', y='tip')Construct models to understand data and make predictions.
First: focus on models which seek to explain outputs (dependent variable) via a linear function of the inputs (independent variable).
Example: If the bill is $20, what will the tip be?
Are there values for and so we can use a equation ?
is the independent variable, and is the dependent variable.
But there are infinitely many linear models that we can use, how do we determine which one is best?
That’s what our loss function solves.
Data Wrangling¶
Recap: Aggregation functions
baby = pd.read_csv("https://raw.githubusercontent.com/jsvine/babynames/refs/heads/master/data/name-counts.csv")
baby.head()We will often want to combine or aggregate data in our analysis.
Most summary statistics are available
baby['count'].mean()np.float64(187.49936886275893)baby['count'].std()np.float64(1590.4001929154851)baby['count'].sum()np.int64(329760765)Aggregating data¶
How many babies are born each year?
Can similarly group data by attributes/columns in pandas:
groupby()return a Series
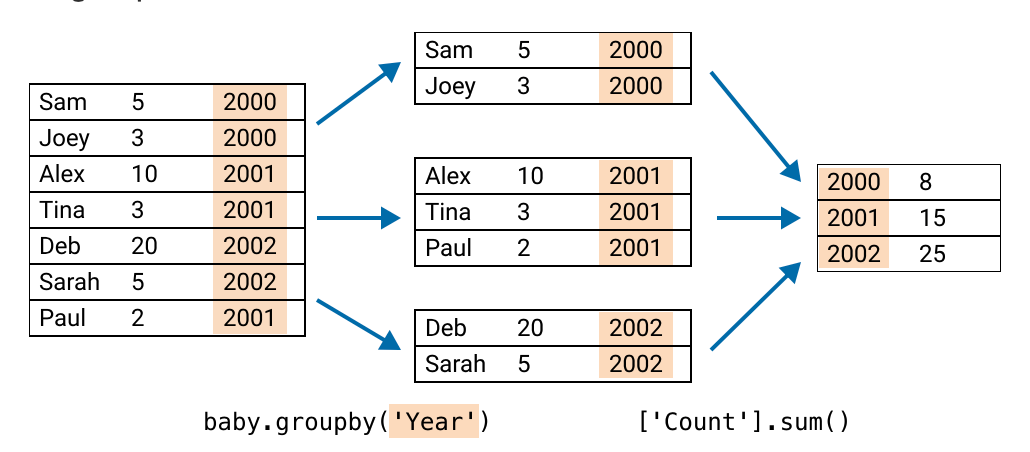
count_by_year = (baby # the dataframe
.groupby('year') # column to group
['count'] # column to aggregate
.sum() # how to aggregate
)
px.line(count_by_year)unique_combos = (baby # the dataframe
.groupby(['sex', 'year']) # make a group for each unique 'sex'+'year'
['count'] # aggregate the 'count' column
.sum() # via summing the 'count' column
.reset_index() # use this sum as the new count
)
unique_combospx.line(unique_combos, x='year', y='count', color='sex')Pivoting¶
When grouping by multiple columns, a useful tool is pivoting.
Idea: use “groupby” attributes to be row and column indices:
mf_pivot = pd.pivot_table(
baby, # the dataframe
index='year', # column to make the new index
columns='sex', # column to turn into new columns
values='count', # column to aggregate for values
aggfunc=sum) # how to aggregate said column
mf_pivotJoins in Pandas¶
Pandas has ways to merge or join information from different tables (similar to SQL, covered at the end of the term).
# gen 1
kanto_df = pd.DataFrame({
"pokemon": ["Bulbasaur", "Charmander", "Squirtle", "Pikachu", "Jigglypuff"],
"type": ["Grass", "Fire", "Water", "Electric", "Fairy"],
"generation": [1, 1, 1, 1, 1]
})
# gen 2
johto_df = pd.DataFrame({
"pokemon": ["Chikorita", "Cyndaquil", "Totodile", "Pikachu", "Jigglypuff"],
"type": ["Grass", "Fire", "Water", "Electric", "Fairy"],
"generation": [2, 2, 2, 1, 1]
})
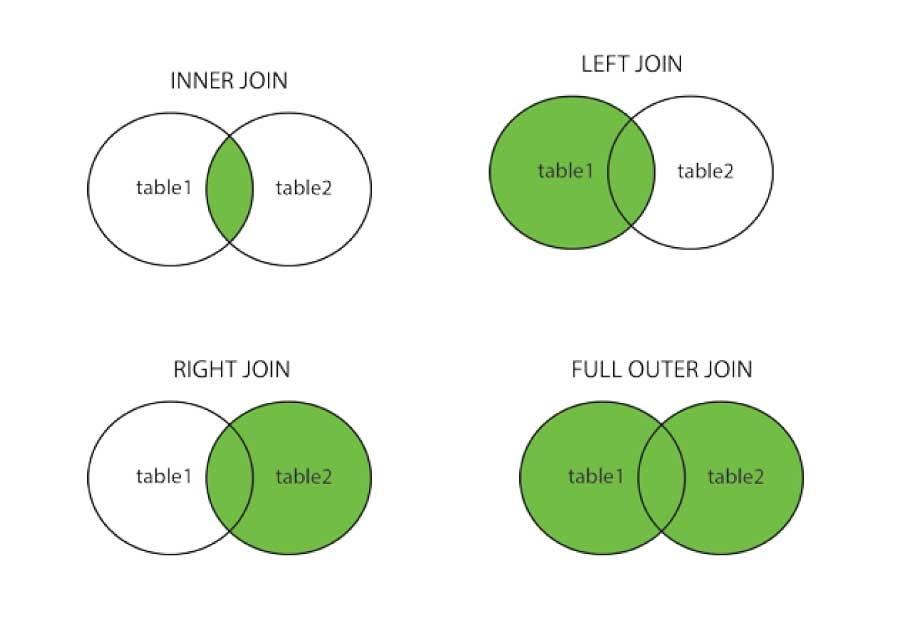
kanto_dfjohto_dfAn inner join only joins the rows that have the key value in both tables:
pd.merge(kanto_df, johto_df, on="pokemon", how="inner")Mathematically can be treated as a intersection
A full outer join adds all the rows of the table on the key value, adding in nulls if a value is missing
pd.merge(kanto_df, johto_df, on="pokemon", how="outer")Notice how it adds _x for left and _y for the right tables, we can specify a suffix as follows:
pd.merge(kanto_df, johto_df, on="pokemon", how="outer", suffixes=("_kanto", "_johto"))A left join adds all the rows from the left table on the key value, filling in null for the missing values
pd.merge(kanto_df, johto_df, on="pokemon", how="left", suffixes=("_kanto", "_johto"))Left-only pokemon have NaN for right table columns.
pd.merge(kanto_df, johto_df, on="pokemon", how="right", suffixes=("_kanto", "_johto"))Right-only pokemon have NaN for right table columns.
Zips and List Comprehension¶
zips: combines iterables into a single iterable.
first_name = ['Alice', 'Bob', 'Charlie']
last_name = ['Hill', 'Irvin', 'Jones']
birth_year = [2003, 2006, 2004]
my_zip = zip(first_name, last_name, birth_year)
print(f'{list(my_zip)}')[('Alice', 'Hill', 2003), ('Bob', 'Irvin', 2006), ('Charlie', 'Jones', 2004)]
for first, last, year in zip(first_name, last_name, birth_year):
print(f"{last}, {first} was born in {year}")Hill, Alice was born in 2003
Irvin, Bob was born in 2006
Jones, Charlie was born in 2004
This is most commonly used in setting up dataframes in pandas
df = pd.DataFrame(list(zip(first_name, last_name, birth_year)),
columns = ['First Name', 'Last Name', 'Year of Birth'])
dfList comprehension is an effective way to traverse lists
nums = [0,1,2,3,4]
sq = [x*x for x in nums]
print(sq)[0, 1, 4, 9, 16]
evens = [num for num in range(10) if num%2 == 0]
evens[0, 2, 4, 6, 8]even_sq = [num*num for num in range(10) if num%2 == 0]
even_sq[0, 4, 16, 36, 64]If you get to the point where you need a nested loop, probably best to fall back to multiple lines
list1 = [1, 2, 3 ]
list2 = [1, 2, 3 ]
result = [i*k for i in list1 for k in list2]
result[1, 2, 3, 2, 4, 6, 3, 6, 9]