Lecture 15 - (21/04/2026)
Today’s Topics:
Natural Language Processing
Text Classification
Sentiment Analysis
NLP¶
In data science, we are often asked to analyze unstructured text or make a predictive model using it. Unfortunately, most data science techniques require numeric data. NLP libraries provide a tool set of methods to convert unstructured text into meaningful numeric data.
Analysis: NLP techniques provide tools to allow us to understand and analyze large amounts of text. For example:
Analyze the positivity/negativity of comments on different websites.
Extract key words from meeting notes and visualize how meeting topics change over time.
Vectorizing for machine learning: When building a machine learning model, we typically must transform our data into numeric features. This process of transforming non-numeric data such as natural language into numeric features is called vectorization. For example:
Understanding related words. Using stemming, NLP lets us know that “swim”, “swims”, and “swimming” all refer to the same base word. This allows us to reduce the number of features used in our model.
Identifying important and unique words. Using TF-IDF (term frequency-inverse document frequency), we can identify which words are most likely to be meaningful in a document.
The TextBlob Python library provides a simplified interface for exploring common NLP tasks including part-of-speech tagging, noun phrase extraction, sentiment analysis, classification, translation, and more.
!pip install textblobRequirement already satisfied: textblob in /Users/ko/Documents/data-visualization-sp26/.venv/lib/python3.13/site-packages (0.20.0)
Requirement already satisfied: nltk>=3.9 in /Users/ko/Documents/data-visualization-sp26/.venv/lib/python3.13/site-packages (from textblob) (3.9.4)
Requirement already satisfied: click in /Users/ko/Documents/data-visualization-sp26/.venv/lib/python3.13/site-packages (from nltk>=3.9->textblob) (8.3.2)
Requirement already satisfied: joblib in /Users/ko/Documents/data-visualization-sp26/.venv/lib/python3.13/site-packages (from nltk>=3.9->textblob) (1.5.3)
Requirement already satisfied: regex>=2021.8.3 in /Users/ko/Documents/data-visualization-sp26/.venv/lib/python3.13/site-packages (from nltk>=3.9->textblob) (2026.4.4)
Requirement already satisfied: tqdm in /Users/ko/Documents/data-visualization-sp26/.venv/lib/python3.13/site-packages (from nltk>=3.9->textblob) (4.67.3)
What Is Natural Language Processing (NLP)?¶
Using computers to process (analyze, understand, generate) natural human languages.
Making sense of human knowledge stored as unstructured text.
Building probabilistic models using data about a language.
Some of the high level tasks we hope to acomplish with NLP include:
Chatbots: Understand natural language from the user and return intelligent responses.
Information retrieval: Find relevant results and similar results.
Information extraction: Structured information from unstructured documents.
Machine translation: One language to another.
Text simplification: Preserve the meaning of text, but simplify the grammar and vocabulary.
Predictive text input: Faster or easier typing.
Sentiment analysis: Attitude of speaker.
Automatic summarization: Extractive or abstractive summarization.
Natural language generation: Generate text from data.
Speech recognition and generation: Speech-to-text, text-to-speech.
Question answering: Determine the intent of the question, match query with knowledge base, evaluate hypotheses.
Unfortunately, the NLP programming libraries typically do not provide direct solutions for the high-level tasks above. Instead, they provide low-level building blocks that enable us to craft our own solutions. These include:
Tokenization: Breaking text into tokens (words, sentences, n-grams)
Stop-word removal: a/an/the
Stemming and lemmatization: root word
TF-IDF: word importance
Part-of-speech tagging: noun/verb/adjective
Named entity recognition: person/organization/location
Spelling correction: “New Yrok City”
Word sense disambiguation: “buy a mouse”
Segmentation: “New York City subway”
Language detection: “translate this page”
Machine learning: specialized models that work well with text
import pandas as pd
import numpy as np
import scipy as sp
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB # Naive Bayes
from sklearn.linear_model import LogisticRegression
from sklearn import metrics
from textblob import TextBlob, Word
from nltk.stem.snowball import SnowballStemmer
%matplotlib inline# Read yelp.csv into a DataFrame.
path = 'https://raw.githubusercontent.com/justmarkham/DAT7/refs/heads/master/data/yelp.csv'
yelp = pd.read_csv(path)
# Create a new DataFrame that only contains the 5-star and 1-star reviews.
yelp_best_worst = yelp[(yelp.stars==5) | (yelp.stars==1)]
# Define X and y.
X = yelp_best_worst.text
y = yelp_best_worst.stars
# Split the new DataFrame into training and testing sets.
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1)pd.Series([True, True, False, False]) | pd.Series([True, False, True, False])
# | takes the first item in the first list and compares it with the second list wit an or condition0 True
1 True
2 True
3 False
dtype: bool# The head of the original data
yelp.head()
# The head of the new data
yelp_best_worst.head()Text Classification¶
Text classification is the task of predicting which category or topic a text sample is from.
We may want to identify:
Is an article a sports or business story?
Does an email have positive or negative sentiment?
Is the rating of a recipe 1, 2, 3, 4, or 5 stars?
Predictions are often made by using the words as features and the label as the target output.
Starting out, we will make each unique word (across all documents) a single feature. In any given corpora, we may have hundreds of thousands of unique words, so we may have hundreds of thousands of features!
For a given document, the numeric value of each feature could be the number of times the word appears in the document.
This technique for vectorizing text is referred to as a bag-of-words model.
It is called bag of words because the document’s structure is lost — as if the words are all jumbled up in a bag.
The first step to creating a bag-of-words model is to create a vocabulary of all possible words in the corpora.
Let’s try text processing in scikit-learn
# Use CountVectorizer to create document-term matrices from X_train and X_test.
vect = CountVectorizer()
X_train_dtm = vect.fit_transform(X_train) #fit and transform in one line on the training data
X_test_dtm = vect.transform(X_test) #only transform on testvect.transform(X_train)<Compressed Sparse Row sparse matrix of dtype 'int64'
with 237720 stored elements and shape (3064, 16825)>237720 / 3064 / 16825 # % of values in matric that are not zero0.004611284184063408vect.transform(X_train).todense()matrix([[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]], shape=(3064, 16825))# Rows are documents, columns are terms (aka "tokens" or "features", individual words in this situation).
X_train_dtm.shape(3064, 16825)# Last 50 features
print((vect.get_feature_names_out()[-50:]))['yyyyy' 'z11' 'za' 'zabba' 'zach' 'zam' 'zanella' 'zankou' 'zappos'
'zatsiki' 'zen' 'zero' 'zest' 'zexperience' 'zha' 'zhou' 'zia'
'zihuatenejo' 'zilch' 'zin' 'zinburger' 'zinburgergeist' 'zinc'
'zinfandel' 'zing' 'zip' 'zipcar' 'zipper' 'zippers' 'zipps' 'ziti' 'zoe'
'zombi' 'zombies' 'zone' 'zones' 'zoning' 'zoo' 'zoyo' 'zucca' 'zucchini'
'zuchinni' 'zumba' 'zupa' 'zuzu' 'zwiebel' 'zzed' 'éclairs' 'école' 'ém']
pd.DataFrame(X_train_dtm.todense(), columns=vect.get_feature_names_out())vectOne common method of reducing the number of features is converting all text to lowercase before generating features! Note that to a computer, aPPle is a different token/“word” than apple. So, by converting both to lowercase letters, it ensures fewer features will be generated. It might be useful not to convert them to lowercase if capitalization matters.
# Don't convert to lowercase.
vect = CountVectorizer(lowercase=False)
X_train_dtm = vect.fit_transform(X_train)
print(X_train_dtm.shape)
vect.get_feature_names_out()[-10:](3064, 20838)
array(['zoning', 'zoo', 'zucchini', 'zuchinni', 'zupa', 'zwiebel', 'zzed',
'École', 'éclairs', 'ém'], dtype=object)X_train.head()6841 FILLY-B's!!!!! only 8 reviews?? NINE now!!!\r...
1728 My husband and I absolutely LOVE this restaura...
3853 We went today after lunch. I got my usual of l...
671 Totally dissapointed. I had purchased a coupo...
4920 Costco Travel - My husband and I recently retu...
Name: text, dtype: strX_train.loc[0]'My wife took me here on my birthday for breakfast and it was excellent. The weather was perfect which made sitting outside overlooking their grounds an absolute pleasure. Our waitress was excellent and our food arrived quickly on the semi-busy Saturday morning. It looked like the place fills up pretty quickly so the earlier you get here the better.\r\n\r\nDo yourself a favor and get their Bloody Mary. It was phenomenal and simply the best I\'ve ever had. I\'m pretty sure they only use ingredients from their garden and blend them fresh when you order it. It was amazing.\r\n\r\nWhile EVERYTHING on the menu looks excellent, I had the white truffle scrambled eggs vegetable skillet and it was tasty and delicious. It came with 2 pieces of their griddled bread with was amazing and it absolutely made the meal complete. It was the best "toast" I\'ve ever had.\r\n\r\nAnyway, I can\'t wait to go back!'X_train_dtm.todense()[:5,:] # equivilent to .head forscipy matrixmatrix([[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]], shape=(5, 20838))list(vect.vocabulary_.items())[:15][('FILLY', 2376),
('only', 15338),
('reviews', 17176),
('NINE', 4360),
('now', 15195),
('wow', 20695),
('do', 10716),
('miss', 14737),
('THIS', 6193),
('place', 16020),
('24hrs', 138),
('drive', 10863),
('thru', 19445),
('or', 15383),
('walk', 20329)]# Finally, let's convert the sparse matrix to a typical ndarray using .toarray()
# - Remember, this takes up a lot more memory than the sparse matrix! However, this conversion is sometimes necessary.
X_test_dtm.toarray()array([[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]], shape=(1022, 16825))# We will use this function below for simplicity.
# Define a function that accepts a vectorizer and calculates the accuracy.
def tokenize_test(vect):
X_train_dtm = vect.fit_transform(X_train)
print(('Features: ', X_train_dtm.shape[1]))
X_test_dtm = vect.transform(X_test)
nb = MultinomialNB()
nb.fit(X_train_dtm, y_train)
y_pred_class = nb.predict(X_test_dtm)
print(('Accuracy: ', metrics.accuracy_score(y_test, y_pred_class)))
# min_df ignores words that occur less than twice ('df' means "document frequency").
vect = CountVectorizer(min_df=2, max_features=10000)
tokenize_test(vect)
('Features: ', 8783)
('Accuracy: ', 0.9246575342465754)
Stop-Word Removal¶
Stop words are some of the most common words in a language. They are used so that a sentence makes sense grammatically, such as prepositions and determiners, e.g., “to,” “the,” “and.” However, they are so commonly used that they are generally worthless for predicting the class of a document. Since “a” appears in spam and non-spam emails, for example, it would only contribute noise to our model.
Example:
Original: “The dog jumped over the fence”
After stop-word removal: “dog jumped over fence”
# Remove English stop words.
vect = CountVectorizer(stop_words='english')
tokenize_test(vect)
vect.get_params()('Features: ', 16528)
('Accuracy: ', 0.9158512720156555)
{'analyzer': 'word',
'binary': False,
'decode_error': 'strict',
'dtype': numpy.int64,
'encoding': 'utf-8',
'input': 'content',
'lowercase': True,
'max_df': 1.0,
'max_features': None,
'min_df': 1,
'ngram_range': (1, 1),
'preprocessor': None,
'stop_words': 'english',
'strip_accents': None,
'token_pattern': '(?u)\\b\\w\\w+\\b',
'tokenizer': None,
'vocabulary': None}# Set of stop words
print((vect.get_stop_words()))frozenset({'anywhere', 'be', 'anyhow', 'he', 'these', 'amount', 'somewhere', 'either', 'with', 'bill', 'hereby', 're', 'becoming', 'below', 'had', 'being', 'four', 'him', 'yourselves', 'ever', 'first', 'you', 'they', 'amongst', 'ourselves', 'anything', 'been', 'nobody', 'ten', 'own', 'latterly', 'thin', 'one', 'fill', 'whereupon', 'behind', 'beside', 'everything', 'forty', 'during', 'call', 'cannot', 'towards', 'though', 'hence', 'therein', 'something', 'who', 'nor', 'others', 'least', 'full', 'another', 'take', 'less', 'hundred', 'besides', 'beyond', 'yours', 'sincere', 'between', 'front', 'twenty', 'seems', 'whoever', 'becomes', 'are', 'since', 'nowhere', 'beforehand', 'enough', 'further', 'done', 'me', 'made', 'among', 'no', 'yourself', 'anyone', 'ours', 'etc', 'move', 'whole', 'once', 'in', 'after', 'than', 'eight', 'was', 'some', 'for', 'whenever', 'out', 'everywhere', 'have', 'serious', 'to', 'twelve', 'upon', 'within', 'an', 'herein', 'there', 'perhaps', 'find', 'sometime', 'if', 'noone', 'never', 'detail', 'because', 'against', 'so', 'see', 'con', 'formerly', 'its', 'neither', 'two', 'even', 'side', 'whom', 'please', 'sometimes', 'more', 'above', 'her', 'mill', 'several', 'very', 'elsewhere', 'before', 'five', 'every', 'few', 'nevertheless', 'any', 'into', 'whereby', 'whose', 'yet', 'whence', 'on', 'everyone', 'himself', 'along', 'couldnt', 'it', 'six', 'again', 'de', 'our', 'found', 'co', 'their', 'empty', 'thereby', 'ltd', 'where', 'hers', 'would', 'must', 'whereafter', 'give', 'someone', 'indeed', 'wherein', 'itself', 'amoungst', 'become', 'well', 'my', 'across', 'wherever', 'down', 'what', 'get', 'many', 'thru', 'those', 'other', 'were', 'fifteen', 'has', 'keep', 'cry', 'will', 'we', 'them', 'she', 'us', 'could', 'none', 'then', 'the', 'hasnt', 'this', 'fire', 'such', 'at', 'through', 'both', 'system', 'most', 'themselves', 'same', 'namely', 'former', 'top', 'afterwards', 'without', 'always', 'rather', 'should', 'sixty', 'how', 'herself', 'else', 'third', 'much', 'alone', 'otherwise', 'now', 'up', 'may', 'back', 'why', 'thence', 'due', 'via', 'describe', 'myself', 'only', 'interest', 'throughout', 'while', 'often', 'am', 'name', 'onto', 'except', 'next', 'is', 'thereupon', 'and', 'already', 'part', 'too', 'three', 'nothing', 'eleven', 'seeming', 'not', 'by', 'toward', 'eg', 'a', 'somehow', 'hereafter', 'show', 'whereas', 'fifty', 'whether', 'all', 'although', 'last', 'latter', 'meanwhile', 'cant', 'here', 'almost', 'hereupon', 'as', 'your', 'that', 'around', 'bottom', 'thick', 'thus', 'i', 'when', 'over', 'seem', 'ie', 'per', 'might', 'whatever', 'put', 'which', 'can', 'of', 'or', 'whither', 'until', 'still', 'mostly', 'about', 'became', 'un', 'however', 'mine', 'inc', 'off', 'go', 'but', 'seemed', 'thereafter', 'anyway', 'his', 'nine', 'each', 'do', 'moreover', 'together', 'therefore', 'also', 'from', 'under'})
# Create a document-term matrix using TF–IDF.
vect = TfidfVectorizer(stop_words='english')
# Fit transform Yelp data.
dtm = vect.fit_transform(yelp.text)
features = vect.get_feature_names_out()
dtm.shape
(10000, 28880)pd.DataFrame(dtm.todense(), columns=features)import nltk
nltk.download('punkt_tab')
def summarize():
# Choose a random review that is at least 300 characters.
review_length = 0
while review_length < 300:
review_id = np.random.randint(0, len(yelp))
review_text = yelp.text[review_id]
review_length = len(review_text)
# Create a mapping from word to column index
feature_index = {word: i for i, word in enumerate(features)}
# Create a dictionary of words and their TF–IDF scores.
word_scores = {}
# (optional: avoid TextBlob dependency issues)
import re
words = re.findall(r'\b\w+\b', review_text.lower())
for word in words:
if word in feature_index:
idx = feature_index[word]
word_scores[word] = dtm[review_id, idx]
# Print words with the top five TF–IDF scores.
print('TOP SCORING WORDS:')
top_scores = sorted(word_scores.items(), key=lambda x: x[1], reverse=True)[:5]
for word, score in top_scores:
print(word)
# Print five random words.
print('\nRANDOM WORDS:')
if len(word_scores) >= 5:
random_words = np.random.choice(list(word_scores.keys()), size=5, replace=False)
for word in random_words:
print(word)
# Print the review.
print('\n' + review_text)[nltk_data] Downloading package punkt_tab to /Users/ko/nltk_data...
[nltk_data] Package punkt_tab is already up-to-date!
review = TextBlob(yelp_best_worst.text[0])
print(review)My wife took me here on my birthday for breakfast and it was excellent. The weather was perfect which made sitting outside overlooking their grounds an absolute pleasure. Our waitress was excellent and our food arrived quickly on the semi-busy Saturday morning. It looked like the place fills up pretty quickly so the earlier you get here the better.
Do yourself a favor and get their Bloody Mary. It was phenomenal and simply the best I've ever had. I'm pretty sure they only use ingredients from their garden and blend them fresh when you order it. It was amazing.
While EVERYTHING on the menu looks excellent, I had the white truffle scrambled eggs vegetable skillet and it was tasty and delicious. It came with 2 pieces of their griddled bread with was amazing and it absolutely made the meal complete. It was the best "toast" I've ever had.
Anyway, I can't wait to go back!
summarize()TOP SCORING WORDS:
lemon
expected
salad
mozzarella
ciabatta
RANDOM WORDS:
dressing
sticking
price
di
satisfied
So, this will not be my best review, especially when I expected so much more from this place.
Lets get this out of the way and on the table first, this ws not a bad place to go, but, it wasnt my favorite by any means. I went in expecting to pay a lot for the meal, and rightfully expected the best food I have ever had, and that was just NOT the case. From the high prices to the limited menu, I would expect this place to specialize in the particular menu items, and would hope to have my taste buds dancing while I shout for more. I didnt.
We started the meal with burratta forno cotto mozzarella. it consists of oven baked burrata mozzarella served with grilled ciabatta, fried eggplant, lemon-truffle vinaigrette and parsley. There were only two tiny ciabatta slices which was not the first complaint. the second complaint would be that the fried eggplant could have used a bit more flavor. (perhaps a little lemon pepper in the batter would have done some good) Lastly, the dish could have satisfied by just having a bit more cheese. This dish was not bad by any means, just expected a bit more with the $12 price of two miniature slices of ciabatta and two thinly sliced pieces of eggplant.
on to the salad. I dont know about you, but, when I order a salad, I expect a salad. this was a salad, just not with any lettuce or salad look. we ordered the caprese di pomodoro. this dish is made with heirloom tomatoes, preserved lemon, herbs, fresh burrata mozzarella and extra virgin olive oil. from the description, i assumed, dont ever assume, that this was going to have some spring mix as a salad base, then have the tomatoes witih cheese and basil, and then the lemon with olive oil as a dressing. WRONG. it was nothing more than what the description said. it was two tomatoes cut in half, with a small amount of cheese and a few basil leaves and then the lemon preserve mixed with the olive oil on top. dont get me wrong, this ws absolutely AMAZING, and I would love to have it again. It is just not what I expected, so, it would have been nice to know what exactly I was ordering for $10.
To make matters worse, our so called salad took about 30 minutes to make its way to the table after putting in the order. it took so long that the chef actually apologized and told management that he was going to send out a soup for us for the wait. we were fine and in no rush, but, when we were already having our food take forever and told we were going to get soup, we expected it. the soup never came.
finally, after waiting for and hour and a half for our main entree, we got our food. it was good, but, nothing to write home about. my pollo portofino was bland to say the least, and was actually a little dry. the potatoes were decent, but again, a bit bland.
my date got the ravioli di mozzarella con salsa all'arrabbiata. the ravioli pasta was so thick that you really couldnt taste the filling, and the sauce was to sweet in my and my date's opinion.
we however did order a side of the risotto parmigiano, and this was just amazing. I am very happy that the recipe was on a poast card that came with the bill. I will be making this at home in the coming week.
for dessert, we ordered pistachio gelato. it was the best gelato I have ever had.
when it comes to a decision of returning to Alto, it will not be high on my list due to being over priced for what you get and all around, just not the best first experience. I will however think of stopping in to get some risotto or gelato to go.
when it comes to good Italian, I think I will be sticking with Italian Gratto or Pane e Vino.
Sentiment Analysis¶
Understanding how positive or negative a review is. There are many ways in practice to compute a sentiment value. For example:
Have a list of “positive” words and a list of “negative” words and count how many occur in a document.
Train a classifier given many examples of “positive” documents and “negative” documents.
For the most accurate sentiment analysis, you will want to train a custom sentiment model based on documents that are particular to your application. Generic models (such as the one we are about to use!) often do not work as well as hoped.
review = TextBlob(yelp_best_worst.text[0])
print(review)My wife took me here on my birthday for breakfast and it was excellent. The weather was perfect which made sitting outside overlooking their grounds an absolute pleasure. Our waitress was excellent and our food arrived quickly on the semi-busy Saturday morning. It looked like the place fills up pretty quickly so the earlier you get here the better.
Do yourself a favor and get their Bloody Mary. It was phenomenal and simply the best I've ever had. I'm pretty sure they only use ingredients from their garden and blend them fresh when you order it. It was amazing.
While EVERYTHING on the menu looks excellent, I had the white truffle scrambled eggs vegetable skillet and it was tasty and delicious. It came with 2 pieces of their griddled bread with was amazing and it absolutely made the meal complete. It was the best "toast" I've ever had.
Anyway, I can't wait to go back!
# Polarity ranges from -1 (most negative) to 1 (most positive).
review.sentiment.polarity0.40246913580246907# Define a function that accepts text and returns the polarity.
def detect_sentiment(text):
return TextBlob(text).sentiment.polarity
#return TextBlob(text).sentiment.polarity# Create a new DataFrame column for sentiment.
yelp['sentiment'] = yelp.text.apply(detect_sentiment)# Box plot of sentiment grouped by stars
yelp.boxplot(column='sentiment', by='stars')<Axes: title={'center': 'sentiment'}, xlabel='stars'>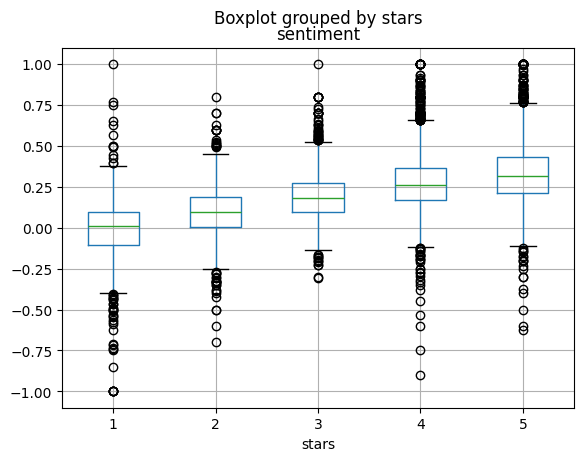
# Reviews with most positive sentiment
yelp[yelp.sentiment == 1].text.head()
254 Our server Gary was awesome. Food was amazing....
347 3 syllables for this place. \r\nA-MAZ-ING!\r\n...
420 LOVE the food!!!!
459 Love it!!! Wish we still lived in Arizona as C...
679 Excellent burger
Name: text, dtype: str# Reviews with most negative sentiment
yelp[yelp.sentiment == -1].text.head()
773 This was absolutely horrible. I got the suprem...
1517 Nasty workers and over priced trash
3266 Absolutely awful... these guys have NO idea wh...
4766 Very bad food!
5812 I wouldn't send my worst enemy to this place.
Name: text, dtype: str# Widen the column display.
pd.set_option('max_colwidth', 500)# Negative sentiment in a 5-star review
yelp[(yelp.stars == 5) & (yelp.sentiment < -0.3)].head(1)
# Positive sentiment in a 1-star review
yelp[(yelp.stars == 1) & (yelp.sentiment > 0.5)].head(1)