Lecture 1 - (29/01/2026)
Today’s Topics:¶
Analytics Building Blocks
Data Collection
Simple Data Storage
Analytics Building Blocks¶
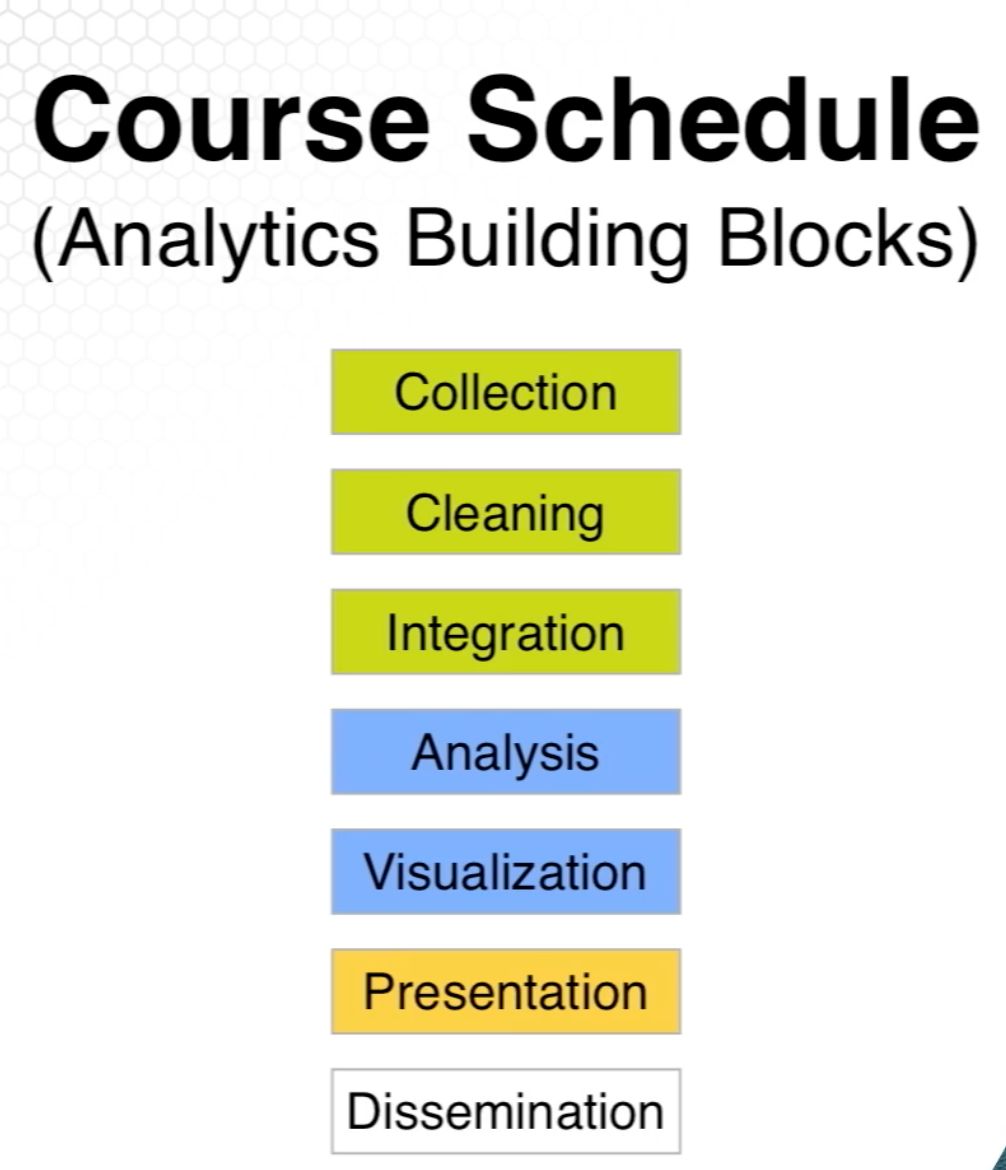
These are the basic building blocks towards analytics, Note:
We can skip some
Can go back (two-way street)
Data types inform visualization design
Data size informs choice of algorithms
Visualization motivates more data cleaning
Visualization challenges algorithm assumptions
How “big data” affects the process?¶
The Vs of big data¶
Volume: “billions”, “petabytes” are common
Velocity: think X/Twitter, fraud detection, etc.
Variety: text (webpages), video (youtube)...
Veracity: uncertainty of data
NetProbe¶
The Problem: Find bad sellers (fraudsters) on eBay who don’t deliver their items
Non-delivery fraud is a common auction fraud
Key Ideas:
Fraudsters fabricate their reputation by “trading” with their accomplices
Fake transactions form near bipartite cores
How to detect them?
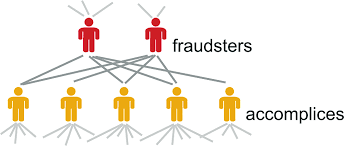

Core idea:
Fraudulent users tend to be connected to other fraudulent users.
Instead of looking at users individually, NetProbe:
Models users as nodes
Models interactions (transactions, messages, relationships) as edges
Infers which nodes are fraudulent by propagating suspicion across the network
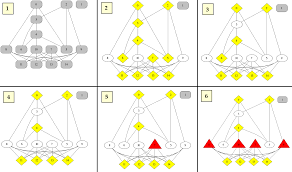
What did NetProbe do?
Collection: Scraping (built a web crawler)
Cleaning
Integration
Analysis: Designed a detection algorithm
Visualisation
Presenation: Paper, talks, lectures
Dissemination: Not released :(
Data Collection¶
How to Collect Data?
| Method | Effort |
|---|---|
| Download | Low |
| API (Application Programming Interface) | Medium |
| Scrape / Crawl | High |
Data you can just download
NYC Taxi data: Trip (11GB)
StackOverflow (xml)
Wikipedia (data dump)
Atlanta crime data (csv)
Soccer statistics
Data that you should access via an API
Google Data API (e.g., Google Maps Directions API)
Last.fm (Pandora has unofficial API)
Flickr
Facebook (your friends only)
Data that needs scraping
Amazon (reviews, product info)
ESPN
eBay
Google Play
Google Scholar
How to Scrape?¶
Goal: Write a program/algorithm to scrape Google Play to collect a million-node network of similar apps
Each node is an app
An edge connects two similar apps
Popular Scraping Libraries
Selenium. Supports multiple languages. http://
www .seleniumhq .org Beautiful Soup. Python. https://
www .crummy .com /software /BeautifulSoup Scrapy. Python. https://scrapy.org
JSoup. Java. https://jsoup.org
Different web content shows up depending on web browsers used
Scraper may need different “web driver” (e.g., in Selenium), or browser “user agent”
As comma-separated files (CSV)
But may not be easy to parse. Why?
1997,Ford,E350But how do we store these when the data gets too big?
Next Lecture: SQL